Introduction to Neural Networks
Convolutional neural networks¶
At the core of convolutional neural networks (CNNs) is their ability to create abstract feature detectors automatically. If carefully combined, you can create a network which has layers of abstraction going from "is there an edge here" to "is there an eye here" to "is this a person".
From a neural network perspective, there is little different in training. You can simply treat each element of the convolution kernel as a weight as we did before. The backpropagation algorithm will automatically learn the correct values to describe the training data set.
CNNs apply a series of filters to the raw pixel data of an image to extract and learn higher-level features, which the model can then use for classification. They usually contain three components:
Convolutional layers, which apply a specified number of convolution filters to the image. For each subregion, the layer performs a set of mathematical operations to produce a single value in the output feature map.
Pooling layers, which downsample the image data extracted by the convolutional layers to reduce the dimensionality of the feature map in order to decrease processing time. A commonly used pooling algorithm is max pooling, which extracts subregions of the feature map (e.g., 2x2-pixel tiles), keeps their maximum value, and discards all other values.
Dense (fully connected) layers, which perform classification on the features extracted by the convolutional layers and downsampled by the pooling layers. In a dense layer, every node in the layer is connected to every node in the preceding layer.
Typical CNN¶
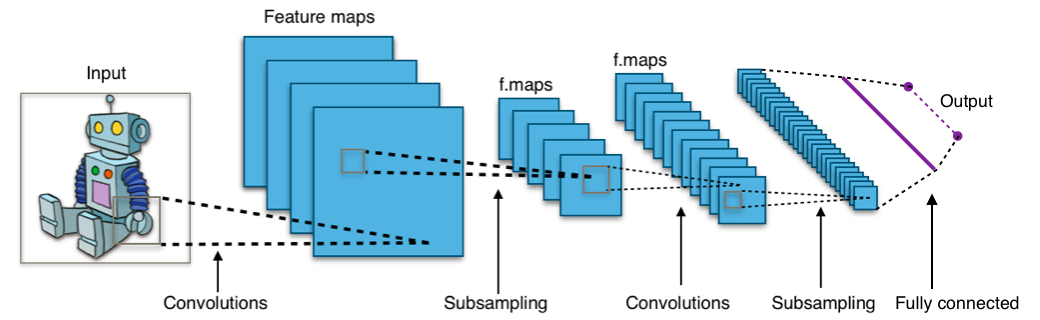
Image segmentation¶

Learn painting styles¶

Nature¶
